Any process or action that requires querying the database and getting results can be optimized by adding database indexes.
An index is used to speed up the performance of queries. It does this by reducing the number of database data pages that must be visited/scanned. In SQL Server, a clustered index determines the physical order of data in a table. There can be only one clustered index per table (the clustered index IS the table)
What is an index?
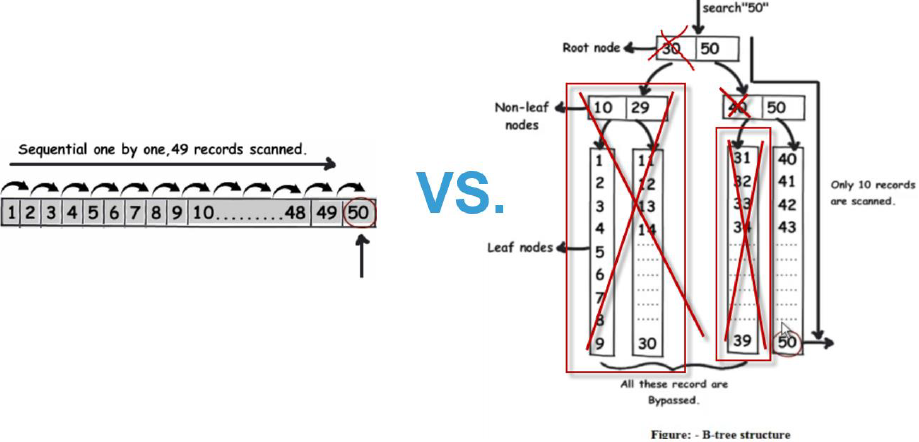
So, what is an index? Well, an index is a data structure (most commonly a B- tree) that stores the values for a specific column in a table. An index is created on a column of a table. So, the key points to remember are that an index consists of column values from one table and that those values are stored in a data structure. The index is a data structure – remember that.
What kind of data structure is an index?
B- trees are the most commonly used data structures for indexes. The reason B- trees are the most popular data structure for indexes is since they are time efficient – because look-ups, deletions, and insertions can all be done in logarithmic time. And, another major reason B- trees are more commonly used is because the data that is stored inside the B- tree can be sorted. The RDBMS typically determines which data structure is used for an index. But, in some scenarios with certain RDBMS’s, you can specify which data structure you want your database to use when you create the index itself.
The SQL Server Database Engine automatically maintains indexes whenever insert, update, or delete operations are made to the underlying data. Over time these modifications can cause the information in the index to become scattered in the database (fragmented). Fragmentation exists when indexes have pages in which the logical ordering, based on the key value, does not match the physical ordering inside the data file. Heavily fragmented indexes can degrade query performance and cause your application to respond slowly.
You can remedy index fragmentation by reorganizing or rebuilding an index. For partitioned indexes built on a partition scheme, you can use either of these methods on a complete index or a single partition of an index. Rebuilding an index drops and re-creates the index. This removes fragmentation, reclaims disk space by compacting the pages based on the specified or existing fill factor setting, and reorders the index rows in contiguous pages. When ALL is specified, all indexes on the table are dropped and
rebuilt in a single transaction. Reorganizing an index uses minimal system resources. It defragments the
leaf level of clustered and no clustered indexes on tables and views by physically reordering the leaf level
pages to match the logical, left to right, order of the leaf nodes. Reorganizing also compacts the
index pages. Compaction is based on the existing fill factor value.